
Gemini 3.1 Pro : Google hausse le niveau de raisonnement
Google a lancé gemini 3.1 Pro le 19 février 2026, avec une promesse simple : mieux raisonner. L’annonce est stratégique, car c’est le premier incrément « .1 » sur la gamme phare Gemini, un format rare chez Google.
L’intérêt pour l’entreprise est immédiat : comprendre ce qui change vraiment, comment y accéder (app, outils, api), et quels usages peuvent en tirer un gain mesurable.
Ce que Google annonce, et ce que ça signifie pour votre SI
Trois messages dominent la sortie. D’abord, un bond en « raisonnement » revendiqué via le score ARC-AGI-2, mis en avant par Google et plusieurs médias spécialisés. Ensuite, des prix inchangés par rapport à la version précédente, ce qui ressemble à une mise à niveau sans surcoût. Enfin, un déploiement large : application Gemini, NotebookLM, gemini api et Vertex AI pour les entreprises ( annonce officielle Google ).
Dans les faits, Google insiste sur ARC-AGI-2 parce que ce test vise des problèmes de logique nouveaux, avec des motifs que le modèle n’a pas « vus » tels quels. L’idée n’est pas de réciter une réponse, mais d’inférer une règle et de l’appliquer. Selon plusieurs reprises de l’annonce, gemini 3.1 Pro atteindrait 77,1% sur ARC-AGI-2 contre 31,1% avant, à score « vérifié » ( Notebookcheck, IT Brief Australia ).
Toutefois, un benchmark n’est pas une recette de production. Il ne dit pas tout de la robustesse, du respect des consignes, ni de la dérive factuelle (les « hallucinations », c’est-à-dire des informations inventées présentées comme certaines). Pour des processus client, juridique ou finance, c’est souvent le critère qui fait échouer un déploiement.
Côté dev : mieux arbitrer la qualité, le coût et la latence
La nouveauté la plus actionnable est le paramètre niveau de réflexion (thinking_level). Il remplace une logique plus fine de budget de réflexion et propose trois paliers : Low, Medium et High. En pratique, Low vise les questions simples et les chats à fort volume, Medium sert pour l’analyse courante, et High (par défaut) cible les tâches longues, comme la programmation ou l’analyse multi-étapes ( documentation Gemini API ).
Autre point clé : la fenêtre de contexte reste annoncée à 1 million de jetons (tokens), ce qui permet de traiter de gros blocs de texte ou de code d’un seul tenant. Concrètement, cela peut couvrir une base de code entière, un lot de contrats, ou des dizaines de comptes rendus, sans découpage agressif. La limite à garder en tête est la sortie : Google indique 64 000 jetons maximum en réponse, donc on peut lire énormément mais pas tout « réécrire » d’un coup ( fiche modèle DeepMind ).
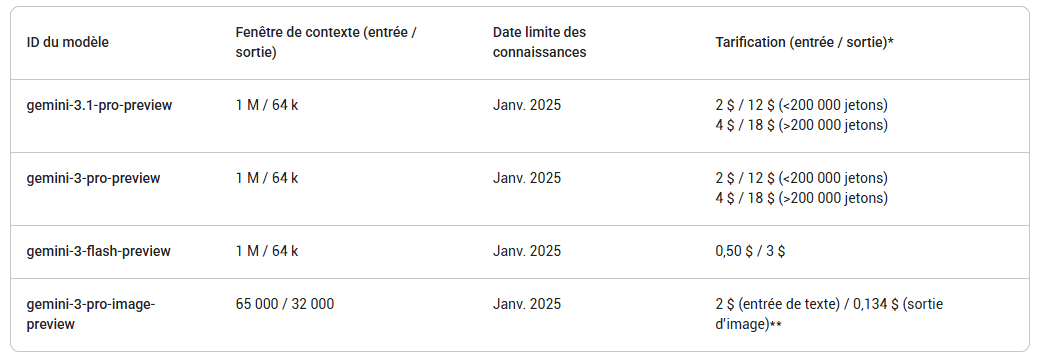
La question qui suit est budgétaire. Google maintient des tarifs de 2 dollars par million de jetons en entrée et 12 dollars par million en sortie, selon les articles qui reprennent la grille, avec un surcoût au-delà de 200 000 jetons par requête ( Verdict, IT Brief Australia ). À court terme, la promesse la plus intéressante est l’efficience : produire une réponse de même qualité avec moins de jetons en sortie, donc moins de facture et parfois une meilleure réactivité.
Enfin, le cache de contexte (context caching) mérite un test systématique. Le principe : si vous réinterrogez le même gros dossier (manuel, base de code, référentiel), vous évitez de repayer à chaque fois l’intégralité de ce qui n’a pas changé. C’est très utile en assistance interne ou en analyse documentaire répétitive, où le « socle » est stable et seules les questions varient.
Multimodal : quand texte, audio et vidéo évitent des étapes coûteuses
Le différenciateur le plus terrain est la prise en charge native de plusieurs médias : texte, image, document PDF (PDF), audio et vidéo. « Natif » veut dire que l’on réduit le prétraitement, comme la transcription ou l’extraction préalable, qui est souvent le poste caché d’un projet. Google revendique cette couverture dans sa communication produit et sa fiche modèle ( annonce Google, fiche modèle DeepMind ).
Pour piloter le coût, le paramètre résolution média (media_resolution) sert à doser la quantité de « budget » consacrée à l’image ou aux images d’une vidéo. En pratique, on vise une résolution élevée pour lire de petits détails (photos, schémas denses), et une résolution moyenne pour des PDF déjà propres. Pour la vidéo, la règle simple est de monter la résolution surtout si du texte apparaît à l’écran et doit être lu précisément ( documentation Gemini API ).
Trois cas concrets ressortent côté entreprise. D’abord, des comptes rendus de réunions enregistrées, où l’audio et les slides comptent autant que les mots. Ensuite, l’extraction d’informations depuis des PDF scannés, avec des tableaux ou des mentions légales. Enfin, l’analyse de démonstrations vidéo pour produire de la documentation, une base de formation, ou des procédures internes.
L’essayer vite : du test individuel au pilote encadré
Pour un test grand public, gemini 3.1 Pro arrive dans l’application Gemini via les offres payantes, avec des limites d’usage plus élevées selon les formules. L’intérêt est de valider des tâches longues et multimodales sans intégration, puis de garder les bons exemples.
Pour la recherche et la productivité, NotebookLM met l’accent sur des réponses « ancrées » dans vos documents. Cela réduit le risque de dérive factuelle, à condition de charger les bonnes sources et de demander des citations internes. Exemples de demandes utiles : « compare ces trois notes et pointe les divergences », ou « liste les décisions et les actions avec propriétaires » ( annonce Google ).
Pour les développeurs, Google AI Studio et gemini api permettent de tester le modèle en préversion, avec un identifiant de type preview selon la documentation. Les réglages à cadrer dès le départ sont niveau de réflexion, résolution média, et votre stratégie de cache. Pour les équipes, cela se traduit par des tests A/B simples : coût par tâche, latence, et taux de réponses réellement exploitables ( documentation Gemini API ).
Pour l’entreprise, Vertex AI et Gemini Enterprise apportent les briques de gouvernance : contrôle des accès, traçabilité, intégration au système d’information, et cadre de déploiement. Dans ce contexte, le statut « preview » compte : il peut limiter les engagements de service et impose un pilote instrumenté avant toute généralisation.
Cinq cas d’usage à retour sur investissement rapide, à cadrer dès le départ
- Support client augmenté : utile quand les politiques sont longues et les échanges s’étirent, avec un historique à conserver. Mesurez la satisfaction client, le temps moyen de traitement et le taux d’escalade vers un humain, puis traitez le risque de réponses erronées par une base documentaire et des règles de validation.
- Synthèse et veille : adaptée aux dossiers volumineux, rapports internes, ou due diligence légère, à condition d’imposer une méthode de vérification. En pratique, exigez la liste des sources utilisées et faites relire les points chiffrés avant diffusion.
- Assistants métiers : intéressant pour RH, finance ou opérations, quand la documentation interne est éclatée. Le gain se joue sur la recherche et la mise en forme, mais il faut des garde-fous : périmètre, données autorisées, et journalisation des usages.
- Analyse de base de code et refactoring : le contexte à 1 million de jetons aide surtout quand les dépendances sont nombreuses et mal documentées. Toutefois, la qualité se prouve par des tests unitaires, une revue de code, et une exécution en environnement isolé.
- Agents de recherche et d’outillage : Google met en avant des progrès sur l’usage d’outils, utile pour automatiser collecte, tri et mise en forme. Gardez l’humain dans la boucle pour les décisions et imposez des étapes de contrôle, surtout quand des sources externes sont consultées.
Claude et OpenAI en face : décider selon le besoin, pas selon un classement
Google mise sur trois arguments : raisonnement, coût et multimodal étendu. Sur le papier, cela favorise les équipes qui traitent beaucoup de contenus variés, et qui veulent industrialiser sans exploser la facture. Les comparaisons de scores circulent, notamment via des tableaux de suivi de modèles, mais elles ne remplacent pas vos propres tests sur données réelles ( Artificial Analysis ).
En parallèle, certains concurrents peuvent rester préférés sur des tâches très factuelles, ou sur des scénarios précis de programmation et d’outillage. Dans ce contexte, une grille simple aide à trancher :
- Votre cas d’usage tolère-t-il une erreur, et quel est le coût d’une erreur ?
- Avez-vous un vrai besoin multimodal (audio, vidéo, PDF scannés) en flux ?
- Êtes-vous contraints par le budget, la latence, ou les deux ?
Un upgrade crédible, mais à valider sur la fiabilité en conditions réelles
gemini 3.1 Pro ressemble à une mise à niveau agressive : gros gain annoncé, prix inchangé, et disponibilité large dans l’écosystème Google. Pour les organisations déjà sur Google Cloud, le passage au pilote peut être rapide et peu risqué.
La mise en production, elle, doit se gagner à la métrique. Démarrez avec un ou deux workflows non critiques, mesurez hallucinations, coût en jetons et latence, puis étendez uniquement si la qualité devient stable et explicable.





