
Gemini rend l’analyse d’images enfin fiable avec Agentic Vision
Les IA « vision » promettent de lire une image comme un humain, mais trébuchent sur les détails. En entreprise, un numéro de série flou, un petit texte ou un tableau dense suffit à déclencher erreurs et approximations.
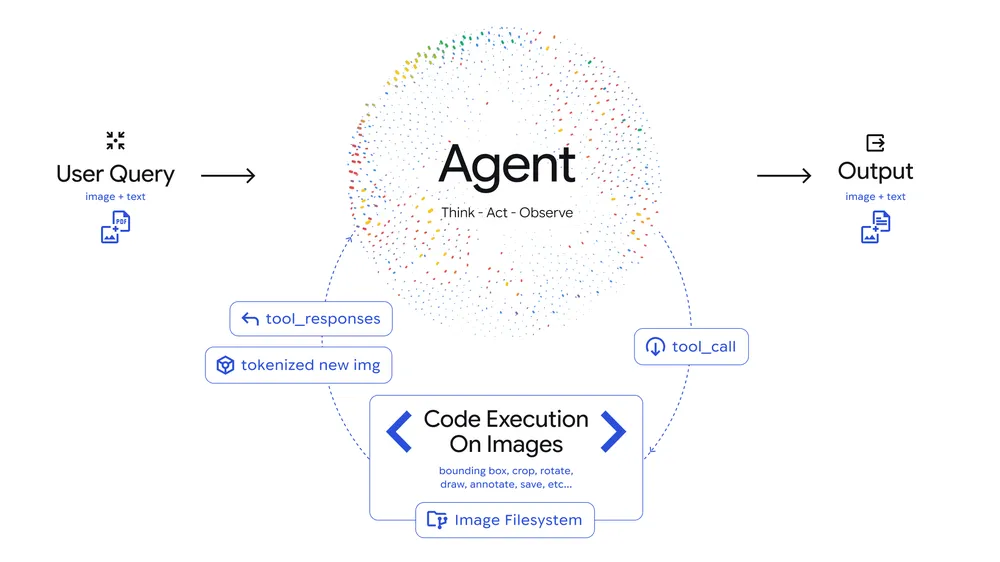
Dans ce contexte, gemini ajoute « Agentic Vision » : l’IA ne se contente plus d’un seul regard, elle mène une investigation itérative et peut exécuter du code Python (Python) pour vérifier ce qu’elle affirme.
Ce que Google lance exactement avec gemini (et pourquoi c’est décisif)
Agentic Vision, tel que présenté par Google, applique à l’image une boucle « Think–Act–Observe » : réfléchir, agir sur l’image, puis ré-observer avant de conclure. L’idée est simple : au lieu de deviner quand un détail est trop petit, le modèle zoome et vérifie.
Trois capacités parlent directement aux équipes métiers.
D’abord, le zoom et le recadrage (crop) sur demande, pour aller chercher du texte fin, un composant, une étiquette ou un repère graphique. Google illustre ce saut avec des exemples où la précision dépend d’une lecture « au pixel près » ( présentation officielle de Google ).
Ensuite, l’annotation : l’outil peut dessiner des boîtes, entourer des zones, numéroter des éléments ou produire une image commentée. Pour une équipe support ou qualité, c’est crucial, car l’IA ne répond plus seulement « il y en a cinq », elle montre ce qu’elle compte.
Enfin, les calculs et graphiques à partir d’images : extraction de valeurs depuis un tableau, normalisation, addition, puis génération d’un graphique, le tout via Python. InfoWorld souligne justement le gain sur le raisonnement visuel, au-delà de la simple description d’images ( analyse InfoWorld ).
Google revendique au passage un gain de qualité de l’ordre de 5 à 10% sur des tests de référence « vision », quand l’exécution de code est activée ( Google ). Ce chiffre compte, mais l’enjeu principal est ailleurs : réduire les « devinettes » lorsque l’information est minuscule ou structurée.
Une boucle simple : question, inspection, preuve, puis réponse
Dans les faits, une requête type suit un déroulé assez intuitif : vous posez une question sur une image, le modèle prépare un plan, génère du code, manipule l’image, ré-intègre le résultat, puis répond.
L’exécution de code change la nature du résultat. Une partie du travail devient déterministe, donc reproductible : si on recadre les mêmes pixels, on obtient le même recadrage, et on peut conserver une trace de ce qui a été fait. Pour l’entreprise, c’est une base d’auditabilité : on peut relire les étapes et comprendre d’où vient une lecture ou un comptage.
En pratique, cette logique se teste dans Google AI Studio et via l’interface de programmation d’application (API) Gemini, en activant l’option d’exécution de code. La documentation détaille le principe, le périmètre et la facturation associée aux jetons (tokens) consommés par les entrées et sorties ( documentation exécution de code, tarifs Gemini ).
Toutefois, il faut être clair sur les limites immédiates. La qualité de l’image source reste déterminante, surtout pour du texte flou ou compressé. Il y a aussi des ambiguïtés visuelles réelles : deux références proches, un reflet, un autocollant partiellement masqué.
Enfin, « raisonner + utiliser des outils » consomme plus de jetons qu’une réponse rapide. Ce n’est pas « gratuit » : on paye en latence et en coût moyen par image, même si Google ne facture pas l’exécution de code comme une ligne séparée ( tarifs Gemini ).
Des scénarios concrets pour gagner du temps sans sacrifier le contrôle
Côté support client, l’intérêt est immédiat. Sur une photo d’appareil, gemini peut zoomer sur une étiquette, lire une référence, repérer un voyant, puis renvoyer une image annotée qui guide le client dans le diagnostic.
En contrôle qualité, l’annotation devient un « rapport » visuel. L’IA peut entourer des défauts, compter des éléments, vérifier une présence ou une absence, puis fournir une sortie exploitable par un opérateur, avec preuves à l’écran.
Pour le commerce en ligne, Agentic Vision sert à vérifier le respect d’un cahier des charges photo : cadrage, lisibilité d’informations, cohérence entre variantes, conformité d’un packaging. Dans ce registre, Google Cloud met en avant l’usage des modèles multimodaux pour traiter des contenus mêlant images et texte ( cas d’usage multimodal Google Cloud ).
En marketing, l’équipe peut contrôler une création : logo bien placé, texte lisible, couleur respectée, éléments manquants. La valeur ajoutée vient de l’annotation des zones à corriger, plus actionnable qu’un commentaire vague.
À court terme, un dernier usage ressort pour les métiers data : récupérer des chiffres depuis un tableau ou un graphique « en image », puis recalculer proprement dans Python et regénérer une visualisation. C’est un bon moyen de limiter les erreurs de calcul « au doigt mouillé » quand un document circule en capture d’écran.
Un mini guide pour passer du test à un pilote produit
Pour les équipes produit, le plus simple est de démarrer sur Google AI Studio, puis d’industrialiser via l’API Gemini ou Vertex AI (Vertex AI) selon vos exigences d’exploitation. Google décrit l’accès au modèle et ses options côté environnements entreprise ( overview Gemini 3, ressources Google Cloud autour de Gemini ).
Le cœur de la réussite se joue dans la manière de cadrer la demande. Il faut dire à l’outil ce qui compte, et comment il doit le prouver.
Points de vigilance (la seule liste à retenir) :
- Définir l’objectif mesurable : « lire la référence », « compter », « vérifier la conformité », pas « analyser l’image ».
- Exiger une inspection systématique des détails : demander explicitement recadrages et zooms sur zones pertinentes.
- Demander une image annotée en sortie quand une décision dépend d’un repère visuel.
- Imposer les calculs via Python pour les tableaux, puis demander le résultat et le détail du calcul.
- Exiger l’incertitude quand la lecture est fragile, avec une preuve visuelle (recadrage) ou un refus.
Ensuite, adoptez un mode « humain dans la boucle » pour les premiers déploiements. Conservez les sorties annotées, et construisez un jeu d’essai avec des images difficiles : flou, reflets, faible lumière, textes minuscules.
Côté indicateurs, suivez peu de métriques mais les bonnes : taux de lecture correcte des petits textes, taux de non-réponse versus hallucination, temps moyen de traitement, coût moyen par image, et satisfaction utilisateur sur les cas traités.
Gouverner l’outil avant qu’il ne gouverne le processus
La confidentialité est le premier sujet. Photos d’atelier, documents scannés, écrans internes : ce sont des données sensibles par défaut, et leur conservation doit être maîtrisée, y compris pour les images annotées.
Deuxième point : l’annotation aide à vérifier, mais elle ne garantit pas la vérité. Il faut définir un seuil d’usage clair : assistance à la décision, ou décision automatisée avec contrôle systématique.
Enfin, la dépendance fournisseur est réelle. La fonctionnalité est récente, et les comportements peuvent évoluer selon les versions du modèle ; les notes de version de Gemini sont un bon réflexe de suivi ( notes de version Gemini ).
Agentic Vision ressemble moins à une révolution magique qu’à une amélioration pragmatique. Elle rend les réponses plus vérifiables, surtout quand l’image contient des détails fins, des tableaux ou des éléments à compter.
Quand ces situations reviennent souvent, le retour sur investissement peut être rapide. Un pilote sur un flux à volume, comme le support ou l’inspection, avec validation humaine et mesures strictes, est le chemin le plus réaliste avant industrialisation.





